Introduction
It is hard to imagine customs control arrangements without commodity codes. This is because there are all sorts of goods with differing characteristics – including shape, form, use, composition, and production stage. Categorisation into codes helps make their control and reporting more manageable. Some practitioners may even refer to commodity codes as ‘buckets’ into which goods with similar characteristics can be sorted – classified – and be made subject to a trade tariff that is specific to the assigned code. In over 200 countries customs commodity codes are now based on the World Customs Organization’s (WCO) Harmonized Commodity Description and Coding System (WCO, 1983) – commonly referred to as the Harmonized System (HS). HS codes also serve as the starting point for preferential origin rules, quantitative restrictions, and tariff quotas. Often, HS-based customs codes are referenced in other regulatory domains, too. This might be in the collection of import Value-Added Tax (VAT) and Excise Duties (e.g., His Majesty Revenue and Customs [HMRC], 2023a), Sanitary and Phytosanitary (SPS) type controls (e.g., Department for Environment Food and Rural Affairs & Animal and Plant Health Agency [DEFRA & APHA], 2023), trade sanctions, prohibitions, and restrictions (e.g., European Commission, 2023d), and many other trade- and cross-border related control measures (Japan International Cooperation Agency [JICA], 2012; WCO, 2013). HS codes also play an important role in the collation and analysis of international trade statistics.
But despite the significance of HS codes in the administration of the cross-border trade and customs environment, determining the correct HS classification is often considered to be difficult. Expert training is usually considered to be necessary (European Commission, 2019b; WCO, 2019). And although strict classification rules apply (described later in Box 1), errors are frequently made. The Auditor General of Canada (AGoC), for example, estimates that 20 per cent of goods brought into Canada during the fiscal year 2015–16 was misclassified (AGoC, 2017). It is no secret, evidenced by many tribunal and court rulings – not to mention the discussions among classification professionals – that classification rules and code descriptions can be interpreted differently. Most customs practitioners can quickly list many examples for which tariff classification is difficult (Table 1).
Given such HS classification challenges, there is a strong case for policy makers to routinely make assistive technologies available to users, and thus help ease their classification burden. Such tools have relevance for the entry and validation of customs codes into electronic customs systems as well as wider single window environments (United Nations Economic Commission for Europe [UNECE], 2020). There are also many online services that require users to be familiar with HS codes (Appendix). And there are many types of resources – especially online – that seek to reduce classification-related challenges. Recently much is also made of Artificial Intelligence (AI) (e.g., WCO, 2023a) – especially where parallels are drawn to innovations elsewhere, such as in biotech developments (e.g., Smyth, 2023), financial (e.g., Tett, 2023) and legal services (e.g., Criddle, 2023).
Specific to the trade and customs domain, AI applications are already being explored within the context of strategic goods controls (Nelson, 2020) and also discussed within the context of customs tariff classification (Lux & Matt, 2021; United Nations Centre for Trade Facilitation and Electronic Business [UN/CEFACT], 2023; WCO, 2022a). Increasingly, regulators are also asked to ensure that new technologies are used responsibly (e.g., Harris & Raskin, 2023). This paper reviews current tariff classification practices and the increasing use of new, assistive technologies – especially those found online. The underlying motivation is to help inform discussions among users, developers, and policy makers about tariff classification requirements, practices, and the responsible use of tariff classification technologies.
Methodology
No research is free from bias. This principle applies even more so when the subject of enquiry is prone to subjective interpretation itself, as is the case for tariff classification, and demands expertise that is usually obtained through many years of training and practice. Academic method is needed to help researchers discipline their personal and particularised experience (e.g., Stake, 2005). An account of the applied methodology helps readers understand the context within which the data has been: obtained; condensed and analysed; as well as interpreted and checked (e.g., Miles & Huberman, 2014).
This paper draws heavily on the author’s personal and professional networks and expertise gained as customs practitioner, policy maker, and later as educator and author (Grainger, 2021). His activities also entailed senior roles in the implementation of electronic online trade tariff tools and online trade information portals in multiple countries. As an expert practitioner researcher, he was thus able to replace what in qualitive research terms may be described as the ‘drift mode’ – a period during which the researcher learns the concepts, locale and jargon of the phenomenon as it occurs (Bonoma, 1985). Being an expert practitioner also enabled him to approach and engage senior policy makers at an advanced technical level.
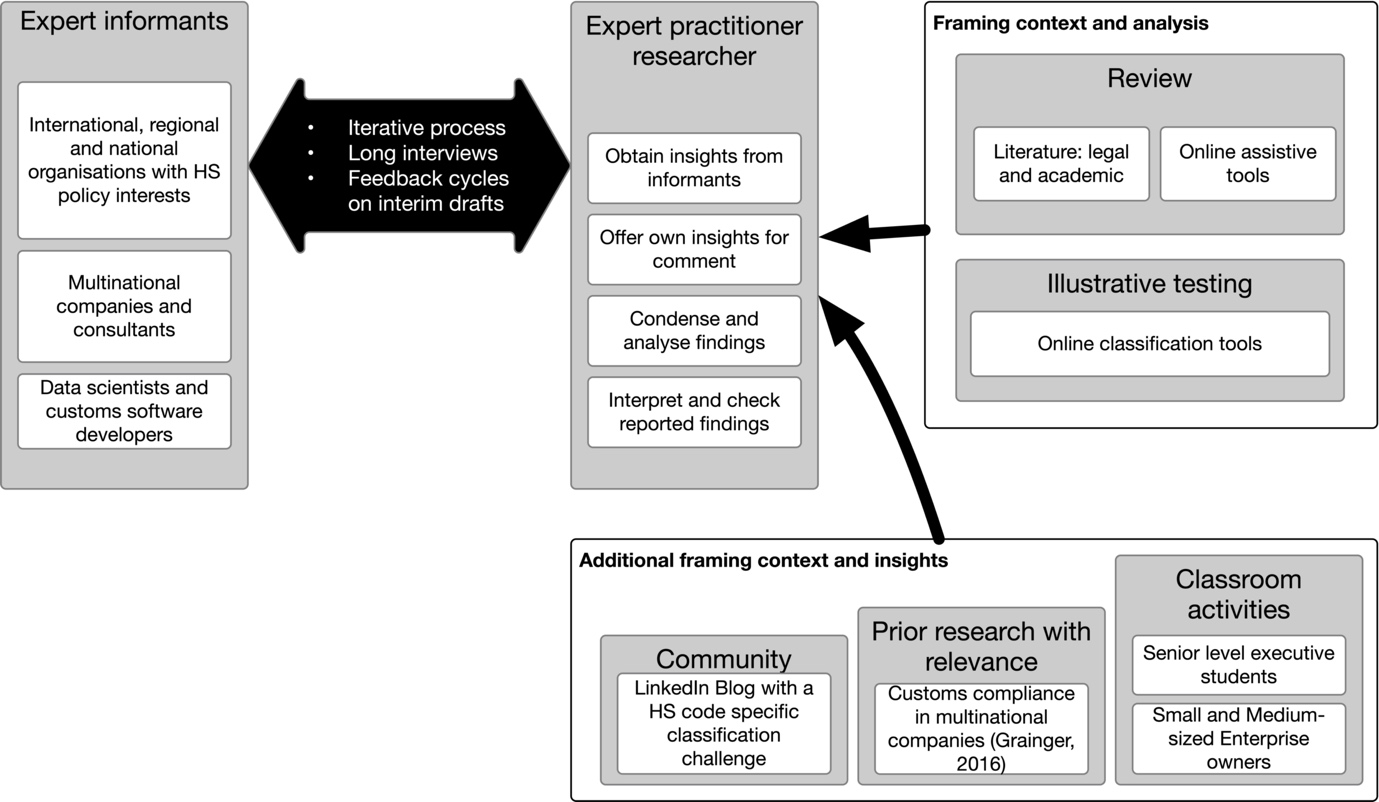
Research reporting and the underlying analysis adopted an iterative process (e.g., Srivastava & Hopwood, 2009) that drew on detailed exchanges (e.g., via email, phone, video calls, in person) with nine senior research informants in industry, at international and regional organisations, and in national administrations who have responsibilities for HS code-specific policy developments, classification decisions, compliance, data science or customs software development. Most exchanges also entailed at least one long interview (McCracken, 1988). Interim drafts with feedback requests from research informants added an additional layer of engagement that shaped the developed analysis. Furthermore, feedback cycles helped ensure that the technical content is correct (with the usual caveats). The adopted iterative process also helped finesse the evaluation of online tariff classification tools (Table 6).
Detailed insights about compliance practices in multinational companies were also gleaned in preceding research (Grainger, 2016) and subsequent classroom type discussions involving senior customs executive from across Europe. Separate classroom activities with small- and medium-sized enterprise (SME) owners revealed further detailed insights about tariff classification ‘short cuts’. Views about classification practices, short cuts, and assistive technologies were also sought by the author on LinkedIn (including a blog post challenging his network to explain how they might classify ‘marmite’). As a condition for frank and open dialogue most research informants insisted on strict confidentiality assurances. Therefore, the names of individuals as well as their organisations that they work for are not cited or referenced explicitly.
A review of relevant academic and legal literature plus online assistive tools provided a detailed framing context. These review activities were conducted using standard academic research databases, taking detailed steer and advice from research informants, and by testing public online tools in person. Test protocols were described in interim draft reports and were also discussed in conversations with research informants. This paper does not aim to be conclusive; tests serve illustrative purposes only to stimulate conversations about the utility and quality of electronic tariff classification tools. But in line with the underlying research objective, this paper does seek to help lend substance to discussions about the HS code and the use of assistive technologies in particular – as might be necessary in HS code-specific policy considerations or in the implementation of tools that aim to ease the tariff classification burden. The building stones of the adopted research framework are summarised in Figure 1.

Customs Commodity Codes and the Harmonized System
Today, almost universally, customs tariff classifications are based on the WCO’s HS. Its nomenclature is structured hierarchically into 21 sections with a total of 99 chapters of which chapters 98 and 99 are reserved for national uses (if required). Chapter 77 is reserved for possible future use. Each chapter is subdivided into headings and subheadings. The first two digits of the HS code represent the chapter numbers (01 to 97), which are extended with an additional third and fourth digit to become 4-digit HS headings. These in turn are usually subdivided by a further fifth and sixth digit into so-called subheadings (WCO, 2022b). National extensions, which often differ from one customs territory to the next, add further digits. As far as possible, codes are arranged in order of the product’s degree of manufacture, or in terms of its technological complexity. For example, the HS code for ‘Decaffeinated’ coffee (0901.12) follows ‘Not decaffeinated’ coffee (0901.11), ‘Flax yarn, multiple (folded) or cabled’ (5306.20) follows ‘Flax yarn single’ (5306.10), and ‘Platinum, unwrought or in powder form’ (7110.11) comes before ‘Other’ forms of platinum (7110.19). Being a ‘living document’ (WCO, 2018a), the HS evolves continuously in response to customs and border control needs. While historically tariffs may have been published using simple text descriptors (e.g. ‘Tea’), such an approach can easily lead to confusion (e.g., whether the descriptor ‘tea’ should also include ‘fruit teas’). By using numeric codes instead, it is possible to be more specific about which goods are subject to control, or if they are not (e.g., by using codes that refer to ‘Other’). The use of codes also makes it easy to differentiate between goods of similar characteristics. For example, ‘Tea, whether or not flavoured’ (HS Heading: 0902) can be differentiated by reference to the following subheadings:
0902.10 - Green tea (not fermented) in immediate packings of a content not exceeding 3 kg
0902.20 - Other green tea (not fermented)
0902.30 - Black tea (fermented) and partly fermented tea, in immediate packings of a content not exceeding 3 kg
0902.40 - Other black tea (fermented) and other partly fermented tea
Such differentiation is particularly useful for policy makers that wish to set different tariffs for similar goods (e.g., for black tea and green tea). It can also assist trade policies that seek to encourage or protect value-added supply chain activity. One example is ‘tariff hopping’; some might use the term ‘tariff jumping’. In the European Union (EU), for instance, unroasted coffee (classified under Heading 0901.11) has an import duty rate of zero, whereas roasted coffee (classified under Heading 0901.21) has an import duty rate of 7.50 per cent. It would thus make sense for coffee roasting facilities to be located within the EU as opposed to where the unroasted coffee beans originate. Alternatively, supply chains could take advantage of lower EU import tariff rates for roasted coffee that originates from countries with access to the Generalized System of Preferences (GSP; 2.6%), GSP+ arrangements (0%), or preferential trade agreements (e.g., zero for Central American countries).
Coded categories are also useful for grouping goods by their specific uses or industries. The HS subheadings for ‘New pneumatic tyres, of rubber’ (HS Heading 4011), for instance, distinguishes between tyres used for: autocars (4011.10); buses or lorries (4011.20); aircraft (4011.30); motorcycles (4011.40); bicycles (4011.50); agricultural and forestry vehicles and machines (4011.70); construction, mining or industrial handling vehicles or machines (4011.80); and ‘Other’ (4011.90) (WCO, 2022b). Customs code definitions may also be informed by regulatory needs set by international conventions, such as those focusing on the illegal trade in drugs, endangered species, environmentally damaging substances and chemical weapons, or multilateral sector specific trade agreements (Table 2). Further granularity might also be deemed necessary at the national level. In the EU, for instance, the duty rates for tyres used on aircraft might be zero if ‘for use on civil aircraft’ (TARIC 4011.30.00.10), but 4.5per cent if ‘Other’ (TARIC 4011.30.00.90) (European Commission, 2023d).
Often, classification codes also contain reference to characteristics that are useful for the administration of other indirect taxes, such as Excise Duties (e.g., by referencing alcohol content) or VAT (e.g., where children’s clothes benefit from special treatment, as is the case for the UK). Quality characteristics with different levels of duty often need to be accommodated, too – as is, for example, the case for various types of butchery cuts (e.g., HS Heading 0202) as well as rice (HS Heading 1006), and wheat (HS Heading 1001). Some customs areas may also extend their national tariff codes to distinguish goods by their recipe. The EU’s Meursing Code does this by adding a further four digits (on top of its 10-digit HS-derived TARIC code) to account for the agricultural composition (i.e., milkfat, milk protein, sucrose/invert sugar/isoglucose, and starch/glucose) in confectionary, pastry, bakery, and dairy products (EU, 2022: 717; Part III, Section I, Annex I). Additional code extensions are also used for reference to export manufacturers that are subject to anti-dumping, countervailing, or safeguard duties. In some cases, there can be hundreds of commodity code-specific extensions. Porcelain or china that falls under the description ’ – Tableware and kitchenware: - - Other’ with the TARIC code 6911.10.00.90, and originating from China, is one such example (European Commission, 2023d).
Categorising goods by reference to classification codes also enables a more refined approach to the collection and analysis of trade statistics. It is perhaps telling that the original impetus for the HS system was shaped during the nine International Statistical Congresses between 1853 and 1876 (WCO, 2018a). Today, we are accustomed to trade statistics that have been compiled by reference to customs commodity codes (e.g., International Trade Centre [ITC] 2023), though other classification conventions are prevalent, too – such as the Standard International Trade Classification (SITC) system (United Nations Statistics Division [UNSD], 2008), which can (with caveats) be correlated to HS subheadings.
A key feature of the HS is that codes are subject to constant review by the WCO (WCO, 2013) and it is formally updated every five years (WCO, 2018a) – though the next update, scheduled for 2028, will be after six years. Updates inevitably result in new commodity codes and descriptions, amendments, or deletions. For example, the HS 2022 edition, when compared to the previous HS 2017 edition, includes major reconfigurations for the subheadings of Heading 7019 for glass fibres and articles thereof; and for Heading 8462, for metal-forming machinery. The many changes to codes and their description can be explored in the WCO’s correlation tables, although extensive updates in text also apply to classification-specific chapters and section notes (Weerth, 2017).
Formal updates at the national level can be more frequent than those of the WCO – for example, annually as is the case in the EU (EU, 2022). In addition, there are also tribunal and court decisions as well as national guidance materials to consider, which are usually issued as and when. And with the evolving responsibilities of customs services – that include revenue collection, trade facilitation, and the protection of society (WCO, 2022c) – categorisation and classification needs are likely to evolve at pace. The need to mitigate climate change among other ‘green’ and sustainability issues is one such policy portfolio with potentially significant HS code implications (WCO, 2023c). The alternative, where the granularity for HS codes is insufficient for control needs, would be for customs administration to draw on additional coding systems – such as those used for customs processing (so-called ‘customs procedure codes’) – or avail themselves of HS Chapters 98 and 99, which are reserved for non-harmonised national requirements (WCO, 2013).
Classification
A key principle of the HS is that there is always only one correct customs commodity code for a given product. That code must be determined by reference to the so-called General Interpretative Rules (GIRs) – of which there are six (Box 1) – and always start with GIR1. GIR1 holds that tariff classification must be in accordance with the description of the heading. Identifying the correct HS Heading may require some understanding – some might use the word ‘intuition’ – about how the HS is structured, and what is covered in its various sections and chapters. Chocolate, for example, if containing cocoa, is likely to fall under Heading 1806 (‘Chocolate and other food preparations containing cocoa’). But white chocolate that only contains cocoa butter and not cocoa belongs to Heading 1704 (‘Sugar confectionary including white chocolate, not containing cocoa’) (Global Affairs Canada [GAC], 2023b). Similarly, an electric toothbrush is ordinarily classified as an ‘Electro-mechanical domestic appliances, with self-contained electric motor, …. – Other appliances’ under 8509.80, and not under 9603.21, which provides for ’ - - Toothbrushes,..'.
Considering such complexities, detailed guidance notes and materials are often essential. These are provided in the form of binding Section and Chapter Notes within the HS nomenclature itself. Not binding but guiding are the extensive WCO’s HS Explanatory Notes that are published by the WCO in addition to the HS (WCO, 2022e). Often, customs authorities also publish their own explanatory notes for tariff classification (e.g., Bundesamt für Zoll und Grenzwirtschaft [BAZG], 2023; European Commission, 2019a; Zoll, 2023), along with guidance specific to particularly challenging classification tasks (e.g., CBP, 2023b; GAC, 2023a; HMRC, 2022). Important to consider, too, are court and tribunal rulings (e.g., Courts and Tribunals Judiciary., 2020), which may define and set further national principles about how the GIRs should be interpreted in specific circumstances (e.g., Lyons, 2008). Prudent businesses that ship goods known to be ambiguous for tariff classification purposes will apply, where possible, for binding tariff classification rulings. These are usually valid for a specified period (e.g., three years for the EU) and reduce the risk of classification-related challenges at border crossings or during post-clearance customs audits.
Inevitably, the process of establishing the correct commodity code must be based on the good’s objective properties and characteristics (Lyons, 2008). Classification workflows that draw on the GIRs may thus begin with an initial assessment of the good’s purpose and its material composition and subsequent locations within the HS. For example, at face value, as explained by Witte and Wolffgang (2021), a furniture table made from wood may lend itself for classification in HS chapter 94 ‘Furniture’ or chapter 44 ‘Wood and Articles of Wood’. But the text in the subheadings, which in this case refer to materials and use, would suggest that the classification under ‘Other furniture’ (HS Heading 9403) in chapter 94 might be more appropriate (Table 3). It is also prudent to check the HS’s respective Section and Chapter Notes to establish whether any specific clarifications, or exclusions apply. And indeed, the notes for chapter 44 clarify that wooden furniture articles belong to chapter 94. Further clarifications, such as for wooden furniture made for specific purposes, or more than one type of material, can be found in in the HS Explanatory Notes (WCO, 2022e), among other public guidance notes and opinions (e.g., European Commission, 2019a).
For most classification experts, probing evaluation questions for working out the most suitable HS Heading are likely to focus on the goods’: composition (e.g., leather or steel); degree of processing (e.g., yarn, fabric, or shirt); intended use or purpose, or function (e.g., for medical, surgical, or veterinary uses); among other criteria like size, weight, method of operation, performance, contents, or ingredients (see Lux & Matt, 2021). In cases of ambiguity, the goods’ essential characteristics may also need to be considered. To give one example, in the case of a ‘Tweety [bird] interactive plush alarm clock’ [an interactive soft toy with sewn-in alarm clock capabilities] it was ruled by US Customs in 2000 (G82479) that the essential character is that of ‘Toys representing animals or non-human creatures…’ (under Heading 9503) and not that of an alarm clock.
Workflows that seek orientation within the HS code can also include the consultation of the WCO’s Alphabetical Index (WCO, 2023b), or similar (HMRC, 2023b; United States International Trade Commission [USITC], 2022). These specialist publications seek to match common types of goods description – listed in alphabetical order – with possible HS Heading contenders. Practitioners can also consult specialist research databases for reference to prior rulings and decisions (e.g., CBP, 2023a; European Commission, 2023a). And, if goods have already been classified, workflows may also include checks for code changes that have resulted from updates to the HS and national extension. Such checks are usually done manually or electronically using correlation tables in which code changes, amendments, and deletions between editions are highlighted (WCO, 2022a).
For chemicals and pharmaceuticals, orientation within the HS can be guided by specialist databases that draw on Chemical Abstracts Service registration numbers (CAS RN) of the American Chemical Society and United Nations Dangerous Goods Numbers (UN, 2021). The EU’s online European Customs Inventory of Chemical Substances (ECICS) consultation database (European Commission, 2023b) is such a tool that can also be used by reference to Customs Union and Statistical Numbers (CUS) and EC [chemical] Numbers. Ammonium Nitrate with the CAS RN 6484-52-2 may thus be matched to the HS code 3102.30 (‘Ammonium nitrate, whether or not in aqueous solution’) or 3602.00 (‘Prepared explosives, other than propellent powders’). Nevertheless, the classification of chemicals and pharmaceuticals is frequently considered to be particularly difficult and can require detailed product specific expertise – prominent experts in this field may have a PhD in Chemistry (listen, e.g., to the podcast hosted by the Pan European Network of Customs Practitioners [PEN-CP], 2023).
Noteworthy, is that classification experts, trainers, and compliance professionals engaged in conversations about this study were quick to share anecdotes that suggest a prolific use of classification shortcuts (Table 4). Where such shortcuts have been taken, the risk for misclassification is likely to be significant. It was also highlighted that the temptation for taking shortcuts can be high when overwhelmed by the compliance burden, as might be the case for untrained or inexperienced staff.
Classification Costs
For most customs practitioners – whether in the public or private sector – a detailed understanding of tariff classification is an essential prerequisite for entering the profession. Customs commodity codes are the foundation upon which most customs controls rest. But the resulting expense associated with classification depends, to a large part, on the scale of classification specific activity, the volume of items that need to be classified, and the appetite for risks that result from misclassification. And perspectives about the costs and effort involved can differ significantly between those administering controls, and those that seek to comply. Many of the costs associated with tariff classification are self-evident, such as the time needed to become familiar with HS classification rules and understanding how to use them (European Commission, 2019b; WCO, 2019). In some countries, formal accreditation as a customs professional might also be necessary (Grainger, 2021; WCO, 2018a). Training costs can thus be substantial. And there is also a set-up cost to be considered. Commercial subscriptions to guidance documents and materials – especially those sold via the WCO Bookshop, for example – are essential for professional customs consultants and experts. There may also be language barriers and translation costs to consider, if operating languages are not the same as the official languages of the WCO (i.e., French and English).
Business compliance costs
These depend largely on the number of goods and their specific characteristics that need to be classified. For many types of businesses, the number of goods that need to be classified can be quite small. This is because they only trade occasionally, or in goods that are relatively uniform and unambiguous from a classification point of view. After establishing applicable codes, the remaining task is to follow code-specific developments in the HS (usually every five years), or national extensions (usually once a year) and then to update the used codes where necessary. Some businesses may draw on the services of specialist consultants or qualified brokers to assist with customs classification tasks. Advance binding tariff rulings issued by the customs administration can give applicants an additional layer of legal certainty – but these take time and effort to prepare.
For businesses with thousands and sometimes hundreds of thousands of items that need to be classified (as can easily be the case for operators in the automotive and retail sector), tariff classification can be an extensive undertaking. If the company has an operational footprint in multiple countries, it also needs to ensure that the correct codes, which can differ by country, are applied for each of those countries. In the event of errors, mistakes, or changes, a good record-keeping system can support conversations with the administration about how to make retrospective corrections. It is usually also prudent to track how commodity codes are used for preferential origin rules and other measures with impact on trade tariffs, so that retrospective corrections – if necessary – can be made. All these activities have a cost. And the implementation and maintenance of robust record-keeping systems is an expensive undertaking.
A common approach to managing tariff classification requirements is to systematically identify and record applicable commodity codes in the company’s electronic systems by reference to unique product identifiers – such as material reference numbers, product catalogue numbers, or so-called ‘stock keeping units’ (SKUs). To keep the classifying task manageable, some compliance managers may distinguish between items critical to their business and those that are less so. Critical items receive close attention to make sure they are always correctly classified. For less critical items, minor non-compliance risks with subsequent implications may be deemed acceptable. Customs compliance managers may mitigate non-compliance risks through systematic probing. Third-party classification audits may be procured to assist with such activities. Robust record-keeping systems enable retrospective corrections where necessary. It is not uncommon for such companies to utilise specialist software to assist with the classification of less critical goods. It is also likely that such companies draw on the services of tariff classification specialists – and these, too, may be assisted by specialist (sometimes propriety) software tools.
Indirect costs that result from misdeclaration, including disputes with the administration, can lead to adverse control outcomes. These include the risk of increased border delays with all their subsequent costs (e.g., Grainger et al., 2018) as well as the time and cost impacts that result from time-consuming customs compliance audits. Penalties and fines can be high. In extreme cases, where misclassification has been found to be deliberate, custodial sentences apply (e.g., British Broadcasting Service [BBC], 2012). An important point to make in this context is that the fear of fines along with the HS’s complex and technical language can be off-putting. New and inexperienced businesses may choose – unless helped – to forgo international trade opportunities. Practical training, guidance, and support – including the offer of free assistive classification tools – can help reduce such hesitancy.
Public administration costs
For public administrations, the costs associated with tariff classification can be significant too. Staff need to be trained in how to use and check them. Detailed guidance materials along with instructions and internal support services are usually necessary to ensure consistently correct application. The ecosystem that maintains tariff classification codes also includes the cost of courts and tribunals. Tariff classification experts within customs administrations are also usually relied upon to assist and advise colleagues in organisations that are less familiar with classification. Subsequently, much of their work relates to the production of guidance materials.
Leading classification experts are also likely to spend some of their time coordinating classification views and opinions at international and global levels, such as through the WCO’s Harmonized System Committee (WCO, 2015) and the drafting of Explanatory Notes (WCO, 2022e). Coordination of views may also be necessary at regional levels (e.g., Association of Southeast Asian Nations [ASEAN], 2023; European Commission, 2019b) and bilateral levels, such as within the framework of FTAs and international customs cooperating committees. There are also public service expectations, including, for example, online and telephone support services along with the publication of additional guidance materials. Often, this is offered as part of a wider online trade support service that includes: customs tariff publications; guidance tools for the reporting of trade statistics; and public tools to interact with statistical trade data. Many traders also expect – for example, by reference to the WTO Trade Facilitation Agreement (TFA) (WTO, 2014) – that advance, binding tariff rulings can be provided within reasonable time frames.
A key cost area can also be the public expense associated with checking, testing, and auditing declared classifications – though in many countries such costs are passed on by the administrations to shippers in the form of customs and inspection fees (Grainger et al., 2018). Larger transport and shipping operators wishing to ensure smooth border clearance processes may also take on some of the enforcement burden. For example, they may check whether the goods descriptions offered by shippers match the provided HS codes. Prudent intermediaries may also check that goods descriptions do not contain any ambiguous wordings. For example, EU guidance about permitted goods descriptions state that ‘Auto Parts’ would be an insufficient description, but that the more specific ‘Automobile Brakes’ or ‘Windshield Glass for Automobiles’ is acceptable (European Commission, 2021).
A common concern by regulators are deliberate misclassifications that result in lower revenue yields. Dishonest operators could, for example, declare a code that has a lower tariff rate, achieve a more favourable preferential origin outcome, or circumvent additional antidumping duties. And the impact of such deliberate misclassification attempts, if not prevented, can be high (CBP, 2020; Thibedeau et al., 2022). Thus, most customs administrations are likely to take actions that seek to reduce such revenue risks (WCO, 2022d). Some administrations may even highlight which specific commodity codes are subject to closer attention (CBSA, 2023). But, where tariff classification mistakes are accidental (‘honest mistakes’), the cost to the revenue is less clear. Anecdotes offered by interviewed officials and customs compliance managers suggest that the likelihood of inadvertently using the wrong classification code with a higher, lower, or the same trade tariff is balanced. The revenue – as far as honest mistakes are concerned – may thus be no better nor worse off. But further research to test this assumption against deliberate misclassification attempts would be prudent.
Practitioners often also highlight that the regulator’s sensitivity about accuracy can differ. For example, pressure for accuracy may be less pronounced among those concerned with trade statistics, especially when analysis tends to deal in aggregates and can also draw on other sources of trade data (e.g., surveys, procurement data, transport data, etc.). Nevertheless, policy makers concerned with the quality of trade statistics are keen to ensure that the datasets collected are as robust as possible. There are several examples where government agencies have procured or developed tools to help businesses with getting classifications right (e.g., Eurostat, 2023; Statistisches Bundesamt, 2023; United States Census Bureau [USCB], 2023). Businesses in the EU that must make intra-EU statistical declarations (referred to as ‘Intrastat declarations’) may also avail themselves of a simplified non-binding ‘self-explanatory text’. A key characteristic of the self-explanatory text is that it aims to be easier to follow and omits much of the HS’s frequent use of ‘Other’ categories. HS Code 0902.20 for ‘Other green tea (not fermented)’, for instance, is described in the self-explanatory text as ‘Green tea in immediate packings of >3 kg’ (Eurostat, 2023).
Electronic classification tools
There are many use cases for assistive tariff classification technologies. As touched upon, tariff classification software is routinely used – under the critical supervision of humans – in companies where thousands, sometimes hundreds of thousands, of tariff classification codes need to be determined and monitored (Grainger, 2016). Some of that software might be configured or developed in-house, or it might be accessed via procured services – such as those offered by customs brokers and tariff classification specialists. Some software solutions can be procured off-the-shelf and are advertised in journals like WCO News, among other places, and are often showcased at trade fairs (e.g., WCO, 2023c).
But use cases have also been reported for the public sector, where commercial tariff classification software has been deployed to compare goods descriptions with the declared commodity codes. The resulting analysis can then be used to identify areas for concern and subsequent customs interventions (e.g., Thibedeau et al., 2022; WCO & WTO, 2022). Potentially, publicly deployed tariff classification technologies can also be used to sense-check (some might use the term ‘validate’) commodity codes before they are declared via electronic means – for example, by asking users whether they are sure the declared codes and goods descriptions are correct. Some interviewees explained that tariff classification technologies can also be used to support tariff classification helpline enquiries via phone or webchat – for example, for directing users to the right subject matter experts (triage). And, it was often suggested by research informants that good tariff-based online business information services are essential for assisting SME businesses in their export ambitions (e.g., to better understand market opportunities, duty obligations, compliance requirements and preferential origin rules).
Increasingly common for public administrations is to make sure their national tariff publications are published online – as might be expected under WTO TFA commitments (WTO, 2014). Many such online tariff publications include functionalities aimed at assisting users with identifying relevant tariff classifications. A broad review of these suggests that there are three types of technological approaches to recommending tariff classifications (Table 5). These are text and keyword enhanced search engines, expert systems and machine learning (ML) tools. The latter two are often also referred to as AI types of technology. Results can be variable which, if not suitably caveated, can potentially leave users with little or no tariff classification knowledge at risk – unless solutions clearly explain how the correct tariff classification has been obtained.
Text and keyword enhanced search engines
Text search approaches draw on the text published in the customs tariff, including the respective commodity code descriptions. A search for ‘Computer’ in the EU’s online TARIC tool (which includes text search functionality) would thus draw attention to a code listed in HS chapter 38 ‘Miscellaneous Chemical Products’ for which one of the TARIC code descriptions includes the word ‘computer’[1] (European Commission, 2023d). The search does not return any results specific to Heading 8471 for ‘Automatic data processing machines’[2], under which computers would normally be classified. Likewise, inexperienced users may be overwhelmed if searching for a ‘paper shredder’ in the United States’ (US) online Harmonized Tariff Schedule (USITC, 2023). This yields 243 search results that refer to commodity code descriptions containing the words ‘paper’ or ‘shredder’– and none for an office paper shredder that might be classifiable under 8472.90.[3] To reduce such confusion, text search functionality may accommodate Boolean Operators that reduce the number of search results. Online ASYCUDA-based tariff publications (ASYCUDA, 2023), for example, can restrict search from ‘Contains Any’ to ‘Contains All’ (e.g., Ministry of Customs and Revenue [MoCR], 2023).
A text search functionality that is keyword enhanced can often offer more suitable results. The search for ‘Computer’ within the online customs tariff of the Maldives Customs Service (MCS) yields the correct HS Heading 8471 (‘Automatic data processing machines’) even though the text for that heading and its subheadings does not contain the word ‘Computer’. Such a search also returns suggestions for classification falling under HS headings specific to chapter 85 that concerns electrical machinery and parts thereof, such as ‘CRT Monitors’ (HS Heading 8528) (MCS, 2023). Given the prevalence of Alphabetical Index-type publications (HMRC, 2023a; USITC, 2022; WCO, 2023b), it is relatively easy to build and develop keyword enhanced search functionality.
Expert systems
Expert systems in their early years of deployment were described as a significant innovation (e.g., Leonard-Barton & Sviokla, 1988) and their use is now widespread. Commercial expert systems for tariff classification have been available for at least two decades; and subsequent to progressive developments have become increasingly sophisticated. Now the public can also access such systems free of charge by using a growing number of online deployments (Table 5). Expert systems are often described as computer programs that are designed to emulate the decision-making process of humans, mainly by applying ‘if-then rules’ (Bidgoli, 2003; Leonard-Barton & Sviokla, 1988). And, expert systems are likely to have two components. One is the knowledge base that represents facts and rules about the commodities described in the HS nomenclature and is typically built by domain experts (e.g., mechanical engineers, minerologists, textile and fibre engineers, etc.). The other is an inference engine that applies logical rules to the knowledge base to deduce new information (built by AI specialists and HS classification experts).
A key feature of expert systems is that users may be required to interact with them before query results are returned. For example, within the context of tariff classification, users may have to answer a set of questions before a tariff code is suggested — especially if the initial goods description and underlying assumptions entered are insufficient for definitive HS classification purposes. Such probing questions by the software about the goods help build a more complete picture of its HS-relevant defining characteristics. These then enable the software to deterministically orientate itself – just like a human – within the HS nomenclature before making a classification suggestion. Such software, as has been explained by developers, usually also relies on sophisticated language models to help make sense of the user’s commercial goods descriptions – for example by recognising that a ‘blow dryer’ is referred to in the HS as a ‘hairdryer’ falling under Heading 8516 (‘Electrothermic hairdressing or hand-drying apparatus’); and that ‘3d printers’ equals ‘Machines for additive manufacturing’ (Heading 8485).
The Canada Tariff Finder is one example of a publicly accessible expert system (Business Development Bank Canada et al., 2023). If tasked with classifying ‘woven men’s blazers’, for instance, the user is prompted to provide further product details, including the blazer’s composition, as it works its way towards the appropriate commodity code. Users can, if they so choose, also change their answers to explore whether this has an impact on the suggested code. Users can also send feedback to the software developers, which is then used to improve the service. In this context, it is worth highlighting that expert system software is only as good as the expert knowledge it has been imbued with. Just like humans, they can fail if the given textual description of the goods is not understood, or if details necessary for making the correct classification decision are missing or out of date. However, where such information is complete, the software can – as highlighted by several interviewees – be remarkably reliable, quick, and intuitive. Other examples of online expert system implementations include the EU’s Eurostat Combined Nomenclature Search Engine (Eurostat, 2023) and the German Statistics Office’s goods list search engine (Statistisches Bundesamt, 2023). Both are designed to assist users with finding the right customs commodity codes for inter-EU statical declarations. Similar expert system technology is also deployed by the USCB (USCB, 2023) to assist exports with determining the correct Schedule B Number (consisting of the six-digit HS code and an additional 4-digit US-code for statistical analysis).
Machine learning
ML approaches in public tariff classification services are a more recent phenomenon – but the underlying ideas date back a few decades. ML is often described as ‘the field of study that gives computers the ability to learn without explicitly being programmed’ – a definition that is attributed to the work of one of its pioneers, Arthur Samuel (Brown, 2021; Samuel, 1959). In practice, ML is commonly referred to as an automated method for searching patterns in data. Techniques include supervised, unsupervised, and reinforcement learning methods (Shaw, 2022). A prominent example of an ML approach to tariff classification is the recently launched ‘AI HS Code Recommendation Platform’ that was developed under the framework of the WCO’s BACUDA Project in collaboration with the Nigeria Customs Service (NCS) (WCO, 2023a). It has been designed to predict the most likely HS code by drawing on a model that uses historical customs declaration data. Answers are presented as a list of recommended HS codes in order of the model’s predicted likelihood (WCO, 2022f). When testing the model for the purpose of writing this paper, it suggested that the correct HS code for a ‘drone’ might be 8525.90 (with a probability of 54.16%), 9007.10 (with a probability of 23.96%), or 8543.70 (with a probability of 21.88%). However, all suggested answers do not appear to match the WCO’s most recent guidance materials, which would suggest a classification that falls under the HS 2022’s new Heading 8806 (‘unmanned aircraft’), nor does it distinguish between drones with utilitarian functions (like photography) and drones used as recreational toys. Another example of ML in tariff classification support services is Nigeria’s online Customs Single Window Service (NCS, 2023), which suggests with 99.65 per cent probability that the classification for a ‘drone’ might fall under HS subheading 8802.11 for –’ - Helicopters: - - Of an unladen weight not exceeding 2 000kg’. It would thus appear that these predictions do not take the drone’s specific characteristics into account, as a human or expert system might do. Predictions also appear to be biased to historic classification practices, including erroneous declaration data, as opposed to the latest requirements. For ML tools to be effective, it is thus important that the data used for training is suitably reliable (Redman, 2018).
Perhaps also noteworthy is that Nigeria’s and the WCO’s online classification tools struggle with interpreting the meaning of user-entered text. Their respective classification recommendations for a ‘mouse’ fall under Heading 8471, which is only appropriate if it were a computer mouse. But no heading suggestions are offered for pet rodents. And, if a user were to enter ‘pet mouse’ into the WCO’s tool, the resulting tariff classification recommendations (perhaps worryingly for the pet owner) fall under Heading 3808 – as might be appropriate for rodenticides. Similar struggles can also be observed in the classification of ‘Jack’ (a connector for headphones or misspelled jacket, but also a type of fish or bird [whiskey jack] as well as a lifting tool and a colloquial term for a famous American drink that is mixed with cola). Although the WCO system is experimental in ambition, the example of its predictions does reiterate that there are two parts to automatic tariff classification. The first is to understand the meaning of the described goods (e.g., is the mouse a living creature or something that you connect to a computer) and second, to then work out where in the tariff that good might be best classified.
Discussion
The choice of tariff classification technology, to a large part, depends on the desired outcome. Most humans, for example, routinely draw on online tariff classification resources that include online tariff publications and tools that can quickly draw attention to applicable explanatory notes and court rulings. Users rely on these, just as they may have relied upon their paper-based predecessors in the not-too-distant past. Such electronic online tools replace paper but are still used in a way that requires users to initially orientate themselves by reference to HS sections and chapters – though keyword lists and personal notations (which frequent users are likely to make) can speed up classification workflows. The ability to conduct text and keyword searches, if well considered, can often – with caveats – be useful for initial orientation within the HS code, too. ML-derived search suggestion may also prompt users to look at headings that may be relevant before selecting the one that is the most appropriate. The search service here, if used responsibly, is assistive in nature. But it is important that guidance and training materials make it explicit that the search suggestions could be flawed.
Expert system approaches, if well-developed, can emulate human expert deliberations and suggest codes in line with the classification-relevant described characteristics. However, users do require assurances that the classification code offered by the expert system is indeed correct. Functionality, which produces a report (which can be kept as a file note, just as a human would) that explains how the classification has been determined by reference to the considered HS-relevant characteristics, the applied GIRs, HS legal notes, national customs rulings and any other authoritative materials, is desirable.
Organisations relying on automatic tariff classification software, as might be the case for companies with very large classification needs (e.g., in the order of tens or hundreds of thousand items), would also have to regularly audit their classifications and continuously commit to updating and training software (just as they might to training staff) – and if necessary, make retrospective corrections. But, such an approach to compliance requires a tolerant and understanding customs administration.
Another point worth highlighting is that at present the reviewed tariff classification technology appears to draw exclusively on text inputs. This begs the question whether future developments might consider alternative data inputs. Some tariff classification tools, for example, accept Chemical Abstracts Service registration numbers (CAS RN) of the American Chemical Society instead of text descriptions. Several research informants also suggests that it would be a good idea to explore how standardised product codes – such as those of GS1 or Amazon’s ASINs – can be used to help tariff classification software better understand the goods that are described.
Image recognition functionality might also be useful for establishing what is described to tariff classification software. There could, for example, be a use case that draws on image recognition capabilities to mine pictures appended to official classification rulings, such as those of the EU (European Commission, 2023c) or within the HS Explanatory Notes (WCO, 2022e). Likewise, it was pointed out by some border management experts that scanning technology is becoming more sophisticated at identifying the elemental composition of goods, thereby offering a potentially useful data source for assessing tariff classifications.
Several research informants also suggested regular competitions or tests to showcase the advantages of one technology or approach over another. This may serve benchmarking purposes, for example, when making procurement decisions, or for driving further innovation and competition. Inevitably, test design would have to be tailored towards the desired outcomes. This paper and its underlying research drew on challenging illustrative search terms like ‘marmite’, ‘paper shredder’, ‘pumps’, ‘chocolate’, ‘drones’ and ‘computers’, among many other terms. Businesses conducting a test for their own purposes may, for example, draw on a cross-section of their product catalogue and test how software solutions perform for their specific needs.
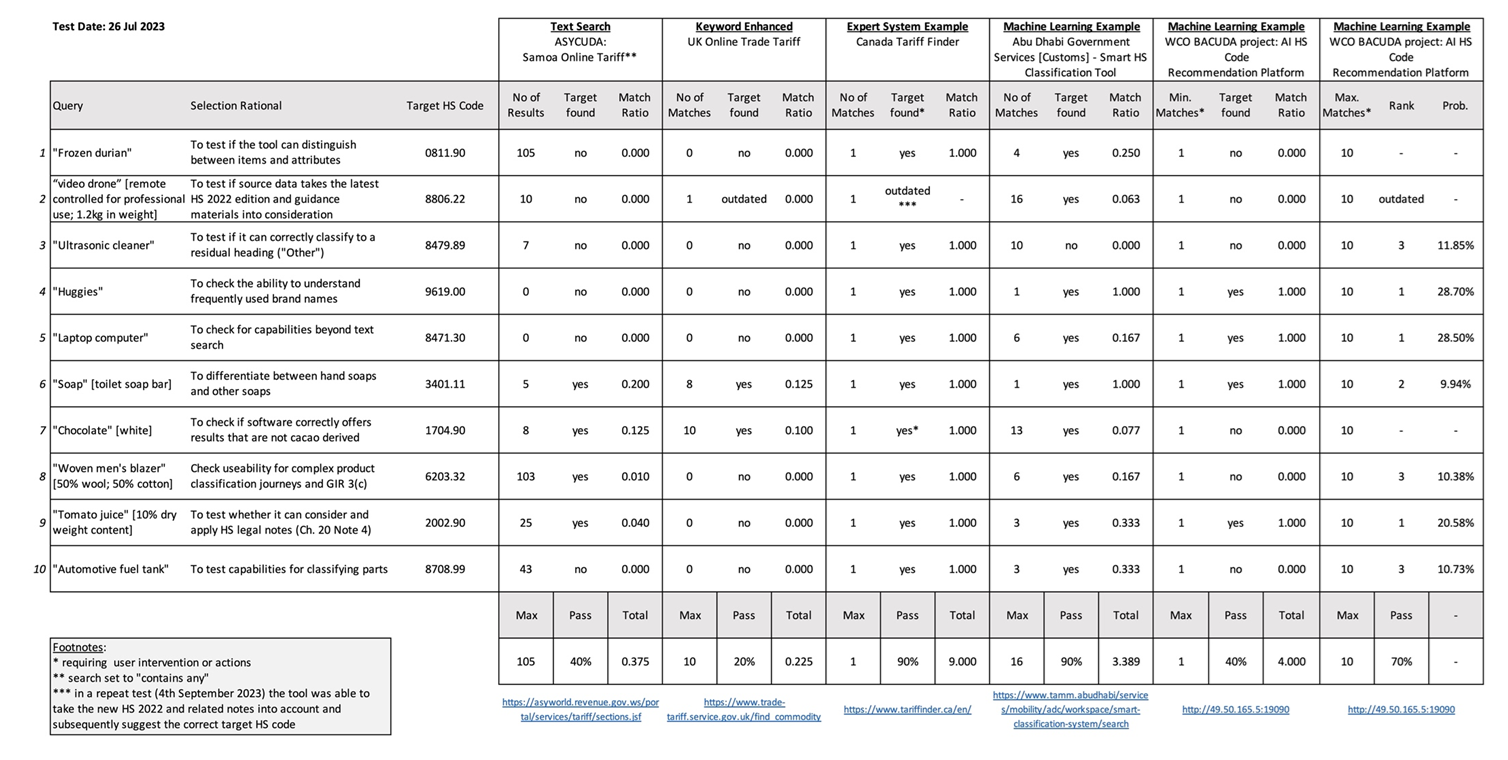
Officials considering the development or upkeep of online tariff classification tools may wish to take inspiration from implementations elsewhere (e.g., Table 1), but also the specific needs of their key stakeholders. While some stakeholders may be quite at home with classification practices, others would need a lot of handholding. Tests could be designed to address frequently asked tariff classification enquiries or made specific to the most declared commodities – which might serve occasional traders with small consignments (like those using e-commerce services) particularly well. More challenging tests may focus on problem areas that humans – and by extension machines – find difficult. Evaluation features criteria might also extend to spelling checks, before queries are processed, and the desired functionalities to help users check suggested codes (e.g., by offering users sight of HS Section and Chapter Notes, other guidance notes, and rulings). Table 6 offers an illustrative example of how the performance of online tools could be evaluated. The example could, of course, be developed further by extending the list of test descriptions, drawing in test suggestions from classification experts, and weighing scores in line with user priorities (e.g., ease of use, accuracy, nil-returns, etc.). It would probably also be worth considering variables that examine practical capabilities and usability (Table 7) – especially if integrated into an online tariff or trade portal type solution.

Conclusion
There is no doubt that the ability to quickly access useful tariff classification-relevant information – like national tariff publications along with WCO guidance materials – helps speed up manual human tariff classification workflows. In applications where AI emulates expert human deliberations, workflows can – with caveats – be automated. Inevitably, the quality of AI-generated results depend on how well the AI has been developed and trained. Just like the work of humans, classification outcomes need to be robust enough to withstand customs audit. And, trust in the generated results needs to be earned. Already, one can witness use cases where goods are automatically classified at scale. And, AI classification software could also be deployed by customs administrations to conduct business audits. It can also be used to evaluate the quality of declared goods descriptions and their commodity codes, and be used to inform strategies that weed out revenue losses that might result from deliberate misclassification attempts. And if built into applications that distribute classification data – such as single window systems – good electronic classification tools can be used to double-check and validate data before it is sent on.
But, conversations should not just limit themselves to the accuracy of current solutions and their implementations. They can be extended to also exploring how software could be better developed or trained, and how that might help build trust and confidence in the suggestions offered by assistive customs classification tools. There may also be scope for practical measures that improve the quality of training data; for example, by removing chunks known to be more prone to error (such as declaration data that has been declared by less experienced or trusted traders) or removing codes known to be outdated. Domain experts have a valuable role to play, be it to help tidy up training data, and ensuring that applied automated knowledge is relevant and correct. For public services, there may also be an audit role to periodically test the quality of automated services provided.
There may also be a case for trade partners to work closely together to explore asymmetries between declared import and export tariff classifications. This could then inform conversations about whether users of specific codes require closer attention or support. Inevitably, when sharing data (including images) for training purposes, conversations also need to be had about regulatory constraints. Regulators may also need to think about standards for safeguarding the quality of training reference data. Historic customs declaration data, unless cleaned, is likely to be inadequate. By contrast, data that has been checked or provided by experts would be more suitable. Publishers of authoritative data, like the WCO, might also need to think about how to make such data available to AI developers.
It may also be a good idea to think about user feedback loops and safeguarding measures – perhaps standards – to make sure that AI is not poisoned with erroneous tariff classification suggestions; or as some might say, to make sure that ML does not go off the rails (see Babic et al., 2021). Much discussion – and research – about the role of the regulator is needed. Maybe, as a starting point, it would also be worth organising regular competitions – like in chess – that pit humans against machines. It is also easy to foresee a near future, which is already beginning to take shape among heavy users of classification software, where customs classification training is increasingly focused on the training machines as opposed to humans.
International trade has a long history in efforts that seek to reduce the impact of trade barriers while ensuring that control measures are in place. The HS is a prime example which, as a living document, has evolved considerably – and is likely to evolve further. But, it is important to also give attention to how codes are published and applied. HS codes are an institution in their own right – one might say ‘part of the furniture’ – that is supported through a wide range of regulations, publications, and increasingly also with electronic tools. Just like the codes themselves, the tools, practices, and procedures that give them life deserve continued attention, too. The prizes that can be derived from well-developed and trained AI technologies, if well implemented and responsibly used, are better compliance outcomes, and improved trade facilitation resulting from lower classification costs.
Funding
The author would like to express thanks to Avalara Inc. for supporting and sponsoring this paper. The work is that of the author alone.
Acknowledgments
Many people from across the global customs community have helped bring this paper into life. This might have been indirectly through casual conversations with the author over the years, or directly as anonymous research informants, interviewees, or peer reviewers. Particular thanks are due to Randy Rotchin at Avalara, my former colleague and friend Dr Duncan R Shaw, as well as Michael Doherty, Gavin Roberts, and Samuel Bautista. Not to be forgotten are the many conversations and insights gleaned from the author’s students at various universities and elsewhere.